Hevo Transformer - Simplifying Data Transformation for Modern Teams
Empowered business teams with instant, natural-language access to their company’s data → +40% adoption in just 6 weeks
Company
Hevo Data
Team
UX Lead (My Role), EIR, Backend Engineers, Data Analyst, UI Developer
Stage
0→1 MVP
Platform
Web (Dashboard, IDE)
Background
Hevo is a modern ETL platform that helps companies sync data from 150+ sources into their data warehouse in real-time. It enables data teams to centralize scattered data but insight delivery still remained a bottleneck for business users.
This gap between data centralization and data accessibility became more pronounced as the org scaled.
📊 Impact
5
existing customers migrated from DBT Cloud
3
DBT Cloud users joined Early Access and opted to migrate
2
net-new users adopted Transformer as their first modeling tool
80%
of users scheduled and monitored jobs without external support during onboarding
❓ The Challenge
DBT CLI was powerful but unintuitive. DBT Cloud addressed some gaps but introduced others: rigid pricing, lack of visibility, and limited project flexibility unless on Enterprise plans.
Although Hevo and DBT Core were often used together (Hevo for ingestion and DBT for modeling) users had to manually switch contexts to orchestrate post-load transformations. This separation introduced workflow friction, required parallel configuration of tools, and made monitoring end-to-end pipelines more complex.
The Opportunity
To create a native transformation experience with Git + Job orchestration atop DBT Core tuned for SMB data teams and directly integrated with Hevo Pipelines.

User Pain Points
Confusing Git setup and job scheduling
DBT Cloud requires Enterprise for multiple projects
Difficult to monitor job failures across stages
🧱 Starting Point
DBT CLI and Cloud both had fragmented experiences:
No visual environments view
Jobs triggered manually or via terminal
CI/Merge workflows needed deep GitOps familiarity
Switching between modeling, execution, and logs was non-trivial
🔍 Process Highlights
Research & Discovery
Analyzed 300+ support tickets related to transformation pain points
Identified top blockers: Git onboarding, job failure visibility, and lack of CI workflows
Spoke with 12+ customers: Ops & Analytics leaders across SMBs
Competitive Analysis
Benchmarked DBT Cloud, Airflow, and Mage

DBT Cloud lacked scalable user control and granular visibility into job states, especially for growing teams managing multiple projects.

Airflow was extremely powerful and customizable, but its infrastructure overhead and complexity made it unsuitable for nimble, 2-5 person data teams.

Mage was geared toward notebook-based workflows and prioritized ease of experimentation, but lacked robust pipeline orchestration features.
Definition
Mapped the journey for 2 primary goals:
New user onboarding from scratch
Existing DBT Core/Cloud migration
Defined MVP success metrics around:
First Project Setup → Connection → Git Integration
Job Orchestration: Deploy, CI, Merge

Ideation & Design Explorations
Sketched multiple landing page IA directions
Explored a job-centric vs project-centric layout
Made a call to anchor on Project → Jobs → Job History to mirror familiar mental models
Iteration & Testing
We showcased early demos to multiple active customers to validate concepts and gather actionable feedback
Some Customer Feedbacks
Found the platform promising and inquired about manifest file access via API for automation highlighting a technical use case we added to the roadmap
MdMail
Appreciated the UI-driven scheduling over Airflow and suggested improvements such as conditional workflows, intuitive dependency visualizations, and better retry logic
Postman
Praised Git-based version control, real-time monitoring, and the Cloud IDE. Requested clarity on pricing and scheduling features, and showed interest in a deeper demo session
Sary
Indicated DAG-style orchestration tied to pipelines would be a key driver for adoption, alongside cost competitiveness against managing open-source stacks.
Warehows
🔗 Connected to the ELT Journey
Research & Discovery
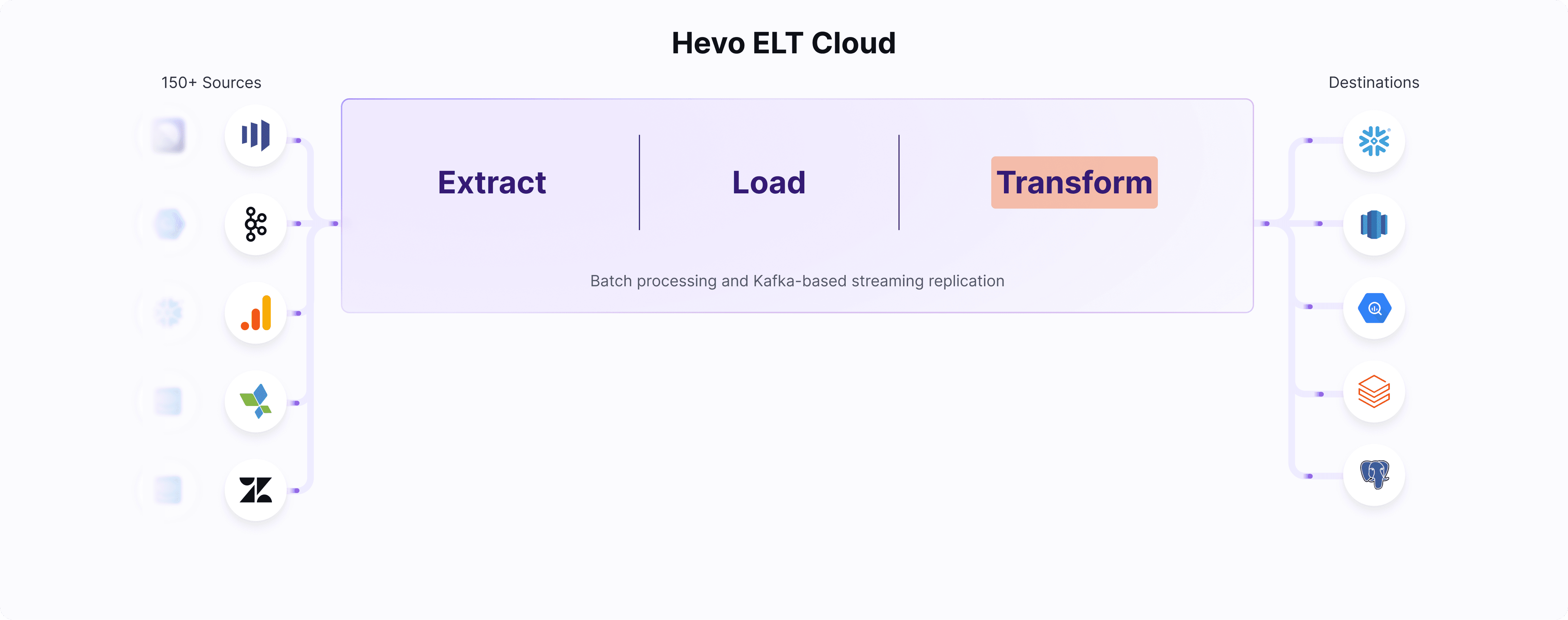
In a modern ELT pipeline, the "T" for transformation is where Hevo Transformer steps in. Once data is extracted and loaded via Hevo Pipelines, Transformer takes over to model it using DBT Core.
This integration removes the need for tool switching. Teams can now transform data right after ingestion, schedule jobs, and monitor outcomes—all within Hevo.
It streamlines the ELT journey, boosts product stickiness, and offers better visibility from ingestion to modeling—all in one cohesive platform.
🧭 Design Principles
To guide the MVP for Hevo Transformer, I focused on five key principles that shaped both UX and system decisions
Design principles I followed:
Stay in One Flow
Avoid tool-switching by keeping ingestion and transformation connected in one system
Frictionless Onboarding
Prioritize speed and clarity in setup to accelerate time-to-first-value
Always Show the State
Transparency in job status, errors, and data flow builds user trust
Future-Ready by Default
Plan for future scale and complexity and multi-stage orchestration
✨ Final Design Highlights
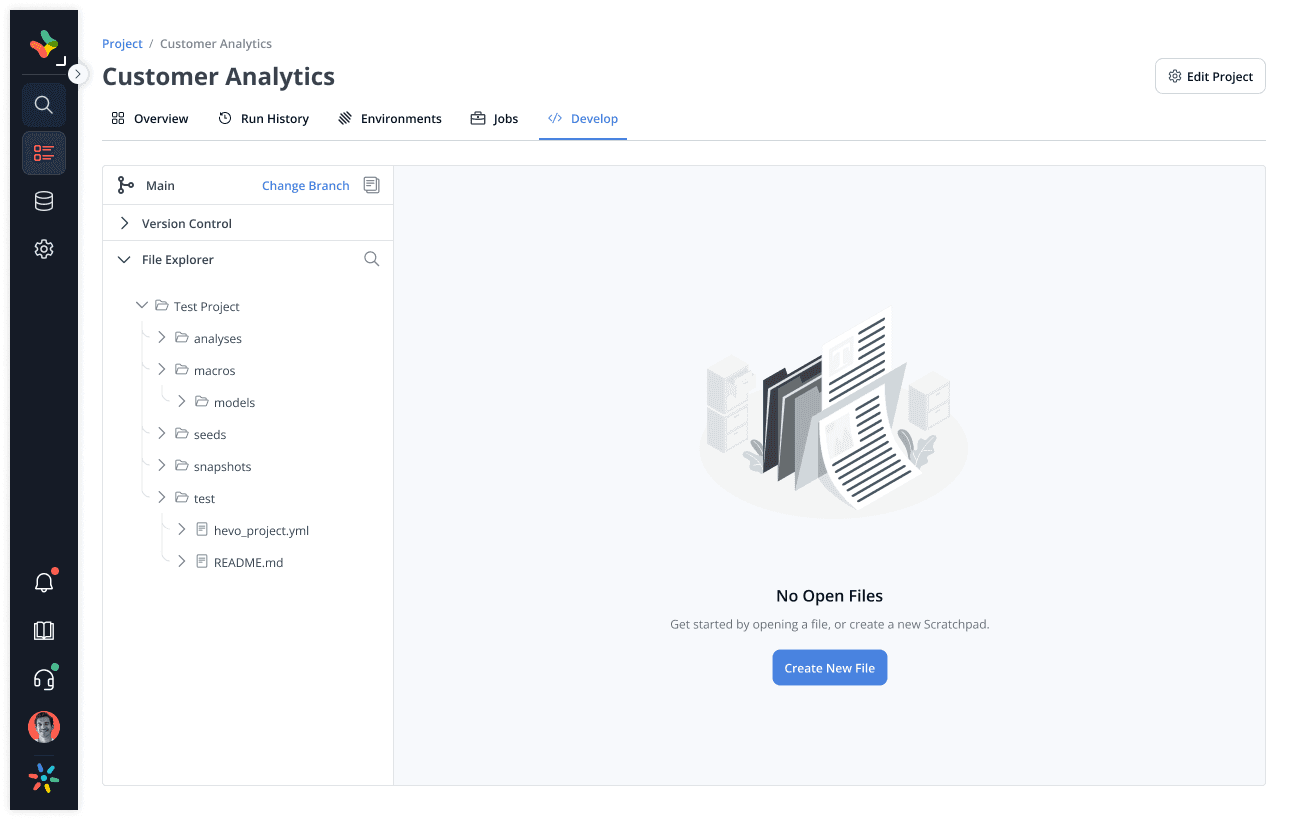
Unified Project View
Create projects, attach connections, environments, and jobs (all in one place) Flexible enough for both devs and analysts
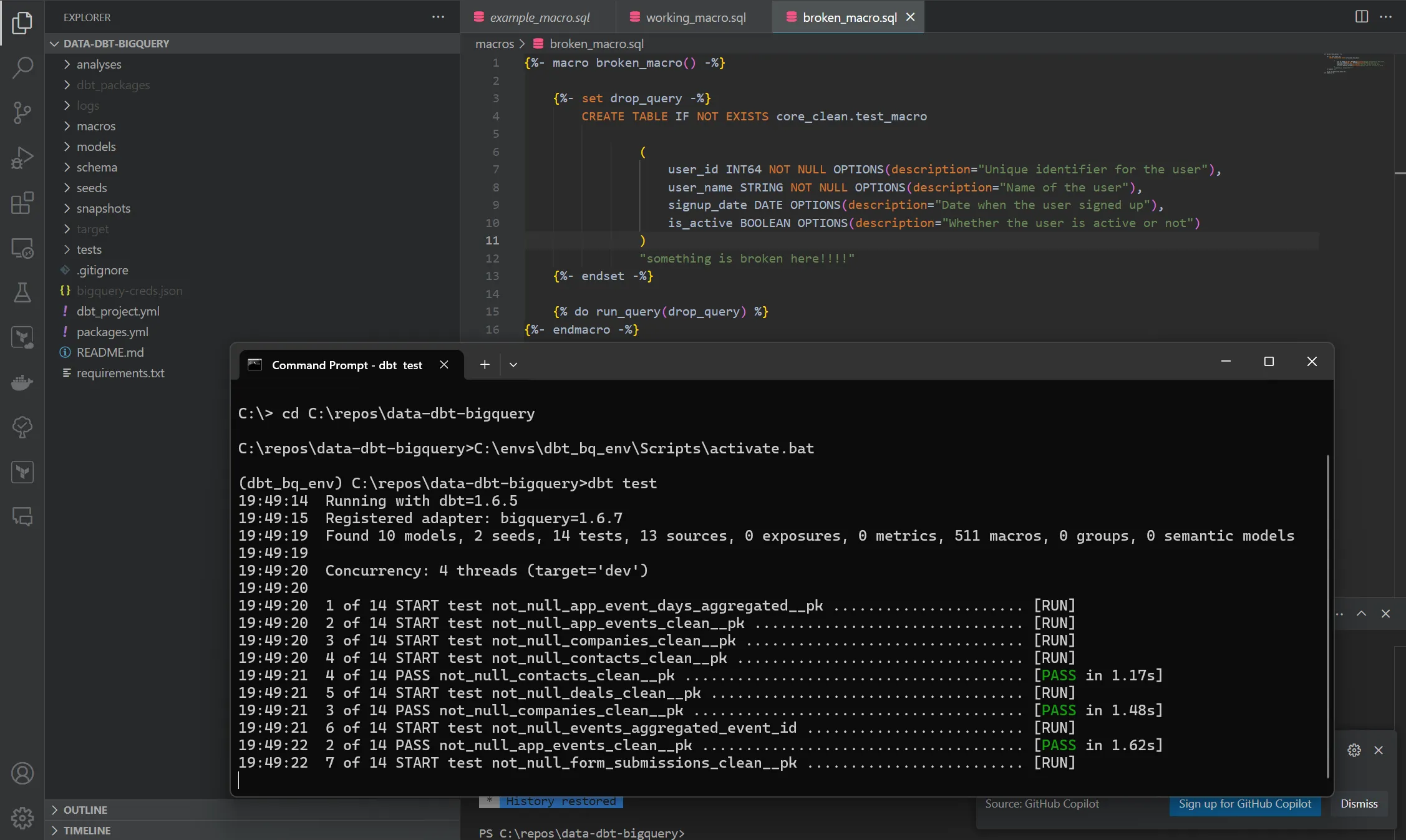
Cloud IDE with Git Integration
Works with GitHub, enforced in IDE (if skipped earlier)
Run models manually, view logs inline
Branch selection + CI-friendly development
Environment & Job Setup
Set up Dev, Staging, Production environments
Configure Deploy, Merge, CI Jobs with schedule, deferral, and conditions
Linked Jobs directly to environments and branches
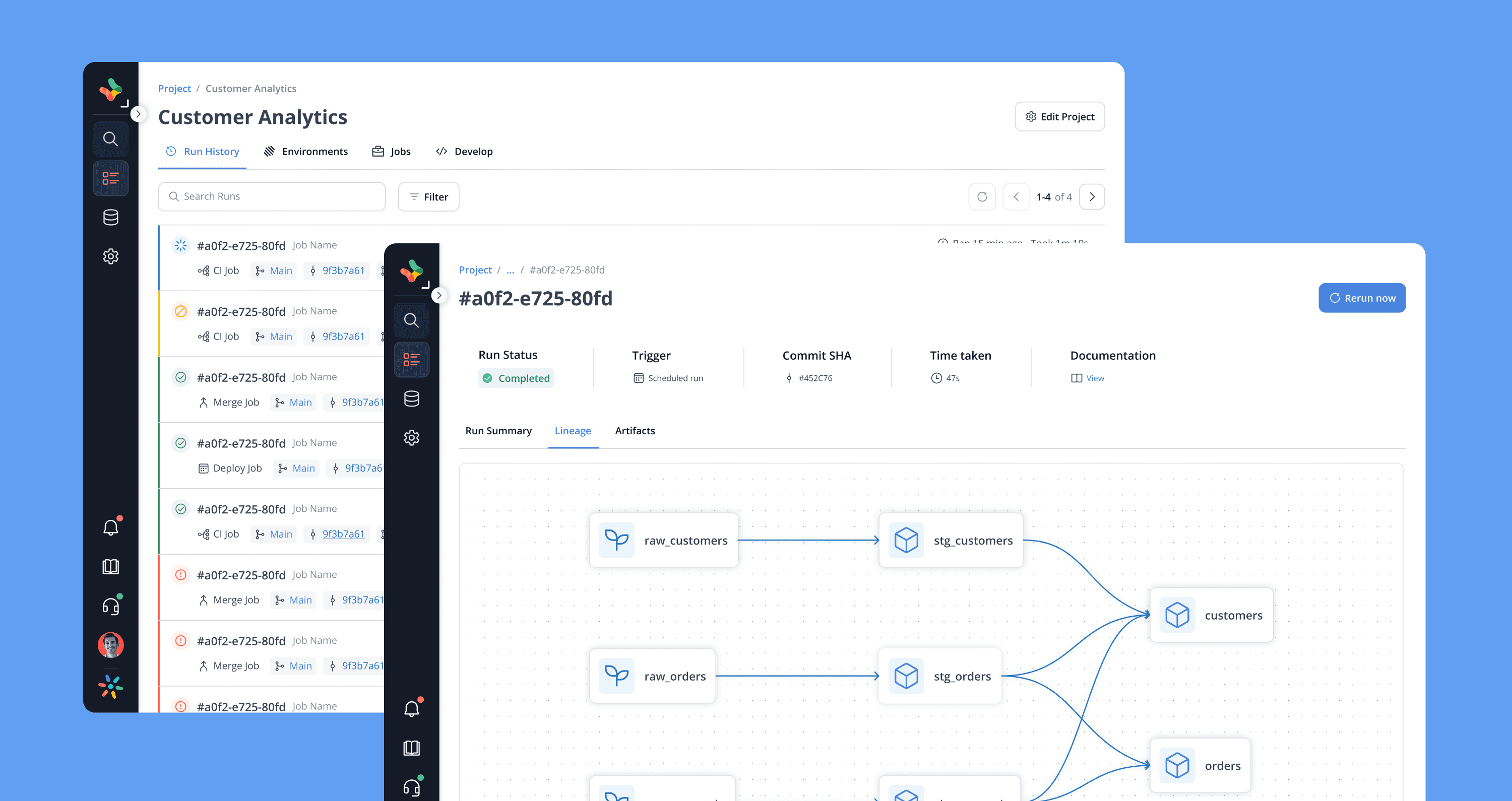
Job Monitoring & Run History
View all job runs across projects
Deep-dive into a specific run for log and error traceability
Patterns inspired by CI dashboards (Jenkins/GitHub Actions)
🧠 Final Reflections
Designing Hevo Transformer wasn’t just about UI, it was about crafting a bridge between powerful but complex tooling (DBT CLI/Cloud) and the everyday workflows of modern data teams.
I learned how to:
Translate deep user journeys into actionable product flows
Prioritize for MVP without compromising extensibility
Design for performance, visibility, and ease in equal measure
If I could go back, I’d bring in more CI/CD integrations earlier and align closer with customer repo structures.
But overall, this was a powerful reminder of what 0→1 design truly feels like
But overall, this was a powerful reminder of what 0→1 design truly feels like